The Urantia Book book indexing system
The platforms
Now that I have an embedded platform working on the Raspberry PI computer, I can now begin the conversion to different embedded systems. First Android smartphones, then Apple smartphones then Native Client for all computers. The indexing system does not use 3d so it can be the first to move to the Android platform and will be placed in the Android app store.
The need for a fast indexing system
First the program can be used to create indexing lookups for all the languages that are translated, irrespective of their fonts by using the current translations.
Next, I’ve found a need for a fast indexing system of the Urantia Book. So many times I’ve needed information fast but found the Internet not suitable when compared to native speeds. I have a working system on Linux and Windows but it has too many problems to be ultimately usable, the first is portability, the second is size. Speed is not an issue.
Also, I use this indexing system in the 3d Virtual Urantia trip to Paradise and would like it efficient with speed and size.
The Description of the program.
This is a description of a fast indexing and lookup system of the content of the Urantia Book. This is already working but it has a few problems. The method I use is instantaneous and works much like the Folio system which was once created for the book in the past. This following method is modernized with a GUI front end and has a coordinated thesaurus look up within the book. That is, a thesaurus that is unique to the Urantia book so that you can easily add multiple word lookups from the thesaurus window. For instance when you select home, abode shows up in the thesaurus window and can be easily added to the word list. This is complete and working in the desktop version.I’ve found that the current databased index works well but is far too large and doubles the information in internal lists as it fills in those internal lists from the database (sqlite db). It takes a long time to download and it takes a long time to fill in these internal lists. So I skip all this wasted time (filling in the lists) and space (doubling the memory) problems by creating a hard programmed list internal to the program, which first, makes for easy transport as the book is internal to the program and it can be traversed mathematically instead of using indexed lists with positions and database indexing schemes. It has the added benefit of being as small and fast.
I have a lot of experiences with this work in publications at various positions I’ve held throughout the industry and I am familiar with the methods here presented.
Most of the mathematics is done up front when creating the index and speeds the manipulations of the words at run time.
The method of creating the index:
The ‘words’ list.
First we create a list of all the words in the book in unique format. No word is repeated twice. This first list is be used when running the program (runtime).
Secondly, the program creates a list with the words and positions within the first list. This second list is used when creating the various following lists, that is, when we create the index (creationtime). It holds a hash based lookup system so that I can look up a word very rapidly when formatting the following lists.
The ‘book’ list
The ‘book‘ list is next. It is a list compacted together with 2 bytes per word in book order and these 2 bytes represent a position in the ‘words’ list. This saves a lot of space as saving the entire word takes one byte for each character of a word. Also this ordered ‘book’ list is used for the ‘index’ and ‘content’ lists which hold a mathematic position within the book.
In this fashion we won’t need to save all the words in the book, it takes only two bytes per word. The recomposition speed in the runtime program is trivial using this method.
The ‘thesaurus’ list
The thesaurus list is formatted this way.
1. It’s position in the ‘words’ list. (2 bytes)
2. The number of words (1 byte)
2. followed by the index into the ‘words’ list of every synonym ending the synonyms for that word. (2 bytes for each synonym)
The ‘content’ list
The ‘content’ list holds all the title levels. It’s formatted this way:
1 The Title type. (1 byte)
2. The position in the ‘book’ list (3 bytes)
3. The number of words in the title. (1 byte)
The ‘index’ list
The index will be the biggest list and is formatted this way.
1. The index position within the ‘words’ list (2 bytes)
2. The number of occurrences within the book. (2 bytes)
3. 3 bytes for each word occurrence in the book. (3 bytes each)
The runtime program
My first issue is screen space. On desktops or tablets it’s not too much of a problem. There is a limited amount of space on the screen of a cell phone. Compounding this problem is the need for fast information exchanges. The program is separated into 6 virtual spaces each with their peculiar way of presenting the information.
1. The word index selection.
2. The references section
3. The Title content and paragraphs for quick perusal and scrolling.
4. The Title Contents of the book
5. The Book content proper.
6. Options
Breakdown of the 6 spaces.
The following comes from the working desktop version.
1. The word index selection.
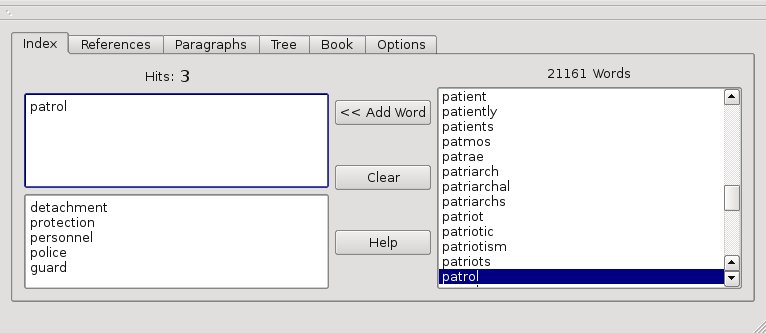
The top left of the screen is the words to lookup in the book. Here you can place the words and operators. ‘home and father’ or ‘(home or abode) and father’ and the like. The bottom left is the a single word within the ‘thesaurus’ list. The right window is the ‘words’ list.
2. The References Section

Here we can scroll through each reference. When selected it jumps to the book content window where the book can be read from that position.
The paragraphs Section
Unfortunately I don’t have a screen shot at this time. I’ll add it later. This section is the same as the references section with the exception that the paragraph contents (words) are added. They can be scrolled. Clicking on a paragraph jumps to the book content window also.
The Tree Section

The tree section is a very fast way to jump to any part of the book. By clicking on the tree leaves one can open that paper/section/subject very rapidly. When double clicked by finger or mouse, the book content window is opened where the book can be read from that position.
The Book Section

This is where the book can be read. The word index selection is highlighted but can easily removed.
System Options Section.
Here are the different options for enlarging or shrinking the size of the text. I will add other options when the cell phone/tablet versions are ready.
Future thoughts
I will eventually add a comment section so that comments can be added to any paper/section/subject/paragraph/sentence of the book. Here I would like to add my internet programs to database the information for anyone who wants to make the comments available on the internet for anyone to peruse.
No comments:
Post a Comment